What happens when (三)HTTP

在前两篇我们经历了通过域名寻找 IP 的 DNS 解析和建立在传输层上的 TCP 连接 ,今天来到最后一步,发送请求,接收响应,并将收到的网页渲染到浏览器上。我们需要应用层上的 HTTP 协议来完成这件事。
什么是应用层协议?我们知道,来自应用层的数据经过逐层封装,发送给指定的 IP 和端口,再经过逐层解析,最终到达目标的应用层。这些应用层的数据才是双方真正要传输的。应用层的数据需要按照约定的格式包装,我们在使用 Socket 编程时,也会设计传输内容的格式。
设计 HTTP 协议最初目的是在万维网上传输 HTML 页面。
一、背景
万维网(WWW),HTTP,HTML,URI,网站,浏览器,这些概念是蒂姆·伯纳斯·李(Tim Berners-Lee)和他在欧洲核子研究组织(CERN)的团队在 1989 年提出的。在这之前,互联网、电子邮件、FTP 都已经发明了近 20 年,个人电脑已经出现,个人、公司、研究机构和政府部门都在使用互联网。万维网和互联网有什么区别?
网路是连接起来的通信设备(例如计算机和打印机)组成的的集合。
互联网络(internet)是两个或多个可以互相通信的网络,最为著名的互联网络是因特网(Internet 大写的I),由成千上万个互相连接的网络组成。
1969年,互联网在美国诞生。1977年,苹果公司推出了Apple II,这是最早的个人电脑之一(售价1200美元)。在1981年,IBM推出了一个苹果的竞争对手IBM PC。 有了网络,有了PC ,可以发电子邮件,可以传输文件。然后呢?人们不知道网络对大众还能有什么用处。没有网站,没有浏览器,没有跳转链接。
首先出现的是 HTML( HyperText Markup Language 超文本标记语言),通过标记让文本更结构化,这些标记仿佛印刷时的标记,能够产生更易读的格式。此外还有链接,它将一个个文档串联起来,点击蓝色带下划线的单词,就会将你带到其他地方。
1 | |
显示出来的效果是这样:

蓝色下划线的单词指向了一个名为 WhatIs.html 的页面。这是第一个网页的一部分,在浏览器按F12可以查看网页的源代码。
伯纳斯·李在 CERN 将超文本同网络结合,连接文档系统,创建万维网(World Wide Web,也称 Web)以及在万维网上获取数据的协议 HTTP。他设计了第一个 Web 服务器与 Web 浏览器,运行了第一个网站和第一个网页。
Lawrence Landweber:人们使用网络做什么?他们使用电子邮件。他们发送文件。但直到1993年,没有什么杀手级应用能吸引真正的人。我的意思是,那些非学术的人,或者不是技术行业内的人。万维网将互联网变成一个资源库,这是迄今为止最大的信息和知识库。突然之间,人们可以在万维网上查询天气或跟踪股市情况,你可以在万维网上做很多事情。 —— 万维网的诞生:互联网的口述历史(上)
The WWW project merges the techniques of information retrieval and hypertext to make an easy but powerful global information system.
The project is based on the philosophy that much academic information should be freely available to anyone.
1993年4月30日,欧洲核子研究组织宣布万维网对任何人免费开放,并不收取任何费用
HTTP的第一个文档版本是HTTP V0.9(1991),这个版本只支持 GET 一种方法,且没有HTTP头,没有状态吗。Dave Raggett 于1995年领导 HTTP 工作组(HTTP WG),并希望通过扩展来使协议变得更加高效。1996年正式引入 HTTP V1.0 (RFC1945),1997年1月正式发布HTTP V1.1(RFC 2068)。
二、HTTP 特性
- 应用层:HTTP是应用层协议,依赖于可靠的面向连接的传输层协议,如 TCP。它自己不保证可靠,不进行重传。
- 请求响应:建立HTTP连接后,由一方(通常是浏览器)发起请求 (request),对方给予响应 (response)。HTTP/1.1协议中共定义了八种请求方法。
- 无状态 (stateless):每条HTTP请求都是相互独立的,互不影响。服务器不会保留以往请求的内容或状态,也就是说没有记忆能力,每次用到之前的信息都要重传。
- 双向传输:浏览器与服务器间的传输是双向的。
- 内容协商:同一页面可能有不同版本,比如不同的字符集。浏览器可以和服务器协商得到最理想版本。
- 支持缓存:浏览器拿到文件的复制,可以保留为缓存。
- 支持中间层:在浏览器和服务器之间可能存在代理服务器等中间层。
三、URL
URL(Uniform Resource Locator),翻译为统一资源定位符,表示的是网络上一个资源的地址,是 URI 的子集(URI 还包括通过名称识别资源的 URN)。浏览器通过 URL 的协议和资源地址,向目标资源发送访问请求。
一个 URL 由协议和资源名称两部分组成,中间用:分隔。如 http://www.eteluna.top/,协议是 http,资源名称是 //www.eteluna.top/。资源名称可以包括主机名, 端口, 路径, 查询参数, 书签, 如:
http://hostname[:port]/path[?quary\][#fragment]
hostname 主机名,域名或IP地址
:port 端口,可选,默认为80
path 路径,服务器上的位置
?quary 查询参数,如?key=value&key2=value2,以?开始,用&连接的键值对
#fragment 书签,以#开始,标记了页面的某个位置,通常用在同一页面不同位置的跳转
四、持久连接和 Cookie
持久连接
在 HTTP 的初始版本中,每进行一次 HTTP 双向通信(发送与响应)都要建立一个新的 TCP 连接。随着时代发展,访问一个网站需要进行的 HTTP 通信次数增多。以 bilibili 首页为例,一次访问进行了 84 次 HTTP 通信(其中许多请求返回的是css js 图片等资源),如果每次都建立新的 TCP 连接,会产生大量开销。
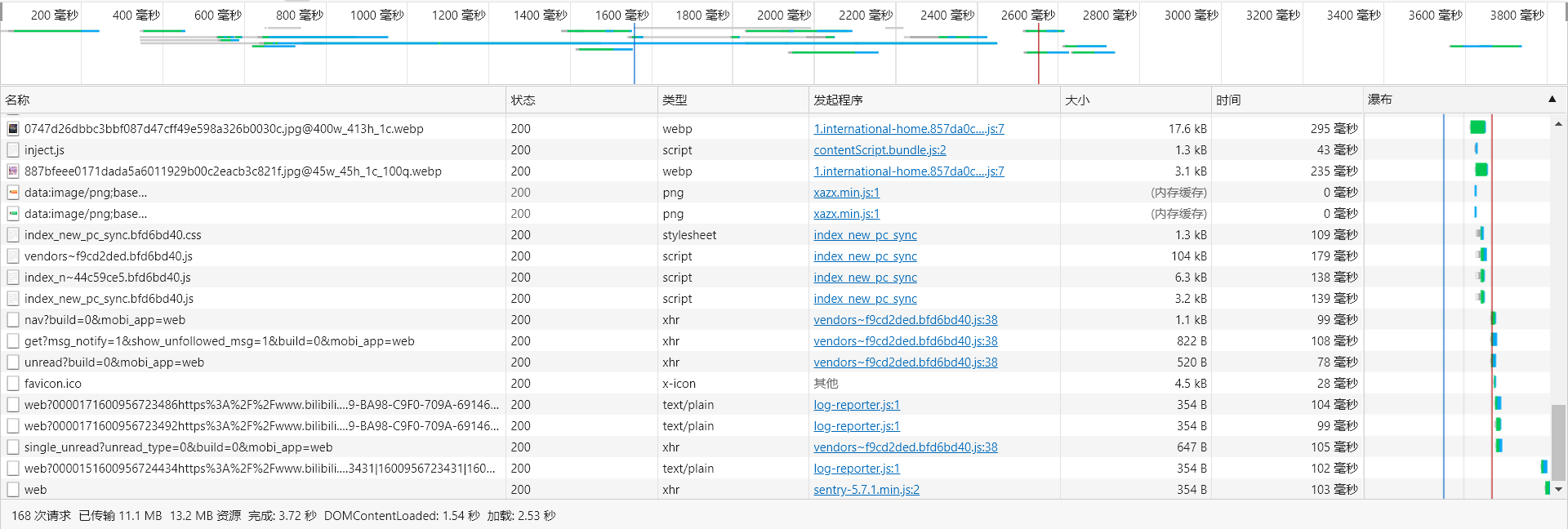
为解决这个问题,HTTP/1.0 之后提出了 HTTP 持久连接(HTTP keep-alive),只要一方没有明确提出断开连接,就会一直保持 TCP 连接状态。
实现了持久连接,就有了管线化(pipelining),可以并行发送和接受多个请求,提升访问速度。
Cookie
HTTP 是无状态协议,服务端不会记录客户端信息,不能根据之前的状态处理新的请求,比如登录信息。这时候打开新的页面,要么重新登录,要么在请求中附加信息。这个附加信息的技术是 Cookie。
当服务器端发送给用户的响应报文中含有 Set-Cookie 字段信息,客户端就会保存Cookie,在下次请求中在报文中加上 Cookie 值后发送出去。这样服务端就能知晓客户端的信息。
Cookie 是保存在客户端上的,而 Session 是保存在服务器上的,如用来记录购物车信息。
五、请求与响应 Request&Response
考虑最简单的情况,获取服务器上的一个静态页面。输入URL,查询DNS,建立了 TCP 连接后,浏览器会发送一个 HTTP GET 请求报文,这个请求的起始行以GET开始,之后是 URL 和 HTTP 的版本号。在建立了 TCP 连接后,URL一般使用相对地址。如对 第一个网页 进行访问的请求是:
1 | |
得到的响应报文是:
1 | |
完整的请求报文与响应报文的格式如下:
1 | |
报文起始行
所有报文都以一个起始行作为开始,请求报文的起始行说明要做什么,响应报文的起始行说明发生了什么。上文的两行就是起始行。
请求起始行包括方法、URL、HTTP版本。方法(method)用来告知服务器操作。HTTP常用方法共以下8种:
GET:获取资源
POST:提交数据
PUT:上传文件( 不验证身份,存在安全性问题 )
HEAD:获取报文首部
DELETE:删除文件(不验证身份,存在安全性问题)
OPTIONS:询问支持的方法
TRACE:追踪路径( 容易引发XST攻击 )
CONNECT:要求用隧道协议连接代理
其中最常用的是 GET 和 POST,前者获取服务器的某个资源,后者向服务器提交数据(如表单)。
响应起始行包括HTTP版本、状态码、原因短语。状态码用来表示HTTP的返回结果,分为五大类:
1XX Informational(信息性状态码) 表示接收的请求正在处理
2XX Success(成功状态码) 表示请求正常处理完毕
3XX Redirection(重定向状态码) 表示需要进行附加操作以完成请求,如请求新的地址
4XX Client Error(客户端错误状态码) 表示服务器无法处理请求
5XX Server Error(服务器错误状态码) 表示服务器处理请求出错
有关方法、状态码的具体内容可查阅 RFC 2068 或 小火柴的前端小册子
报文首部
报文首部由字段名和字段值构成,中间用冒号分隔。
1 | |
以之前的访问为例,请求首部:
1 | |
- Host: 请求的主机名,一个IP上可能部署有多个主机,需要提供主机名.
- Connection: keep-alive 保持持久连接,close 则断开连接.
- Cache-Control: 操作缓存的工作机制.
- User-Agent: 客户端浏览器的种类.
- Accept: 客户端支持的媒体类型和优先级q.
- Accept-Charset: 客户端支持的字符集和优先级,如unicode.
- Accept-Encoding: 客户端支持的内容编码及内容编码的优先级顺序, gzip:由文件压缩程序gzip (GNU zip) 生成的编码格式 (RFC1952),采用 Lempel-Ziv 算法(LZ77)及32位 CRC .
- Accept-Language : 客户端接受的自然语言集,中文英文等.
响应首部:
1 | |
- Date: 报文创建的日期和时间.
- Server: 服务器应用程序.
- Accept-Ranges: 是否能处理范围请求,可指定的字段值有两种,可处理范围请求时指定其为 bytes,反之则指定其为 none.
- Content-: 与实体内容有关的信息.
- ETag、Last-Modified:缓存标识符.
六、本地缓存
浏览器可以将请求的静态文件缓存,以备下次使用,提高访问速度。分为强制缓存和对比缓存两种模式。
在强制缓存下,命中本地的缓存则直接使用,未命中则去请求服务器。在对比缓存下,命中本地缓存后还要请求服务器验证缓存标识的数据是否失效,只有未失效时使用本地缓存数据。 即强制缓存如果生效,不需要再和服务器发生交互,而对比缓存不管是否生效,都需要与服务端发生交互。
对比缓存的步骤如下:
- 第一次请求,将服务器传输的数据和缓存标识符一起缓存。
- 再次请求数据,将缓存标识符发送给服务器,服务器根据缓存标识进行判断比较,成功则返回304状态码,通知客户端比较成功,可以使用缓存数据。否则返回新的缓存数据和缓存规则。
在HTTP1.1中,缓存在报文中最重要的规则是 Cache-Control
Cache-Control 取值包括 private、public、no-cache、max-age,no-store,默认为private。
private: 客户端可以缓存
public: 客户端和代理服务器都可缓存
max-age=xxx: 缓存的内容将在 xxx 秒后失效,服务器可以将最大使用期 max-age 设置为零,从而在每次访问的时候都进行刷新
no-cache: 需要使用对比缓存来验证缓存数据
no-store: 所有内容都不会缓存,强制缓存,对比缓存都不会触发
对比缓存中,重要的是缓存标识符。
服务器传输数据时,在头部会加入 Last-Modified 字段 ,这是资源的最后修改时间。在再次请求时,发送方在请求头部传输 If-Modified-Since 字段, 通过此字段通知服务器上次请求时,服务器返回的资源最后修改时间。如果页面最后修改时间晚于它则返回 200 处理请求,否则返回状态码304 Not Modified,浏览器显示缓存页面.
此外,还有服务器会返回独有的标识符 Etag ,优先级高于 Last-Modified,它的内容不是时间,而是一串字符,如上文例子中的 ETag: "40521e06-8a9-291e721905000",再次请求时使用 If-None-Match: "40521e06-8a9-291e721905000" 服务器它与资源的标识符比对,一致则响应 304 使用缓存,不一致则响应 200 并传输新的数据和缓存规则。
使用 Etag,可以解决过期时间已到,而服务器的资源没有更新,使用 If-Modified-Since 会重新传输相同资源的问题。